
I Built Multilingual Children's Books With ChatGPT in 2022 and They Still Get Purchased
In late 2022, ChatGPT was still new. There were no AI agents. No sophisticated automation pipelines. No elegant tools that talked to each other seamlessly. But I saw something in the early LLMs that felt underappreciated: they could translate content not just adequately, but well.
I have two young children. Our house was full of books in 2022 - books about shapes, colors, emotions, how to be proud of yourself.
Then a friend made a throwaway comment that changed how I saw the entire landscape.
"I wish we had these kinds of books in my language."
It wasn't a plea. It was just an observation during a casual conversation about parenting. But it stuck with me because I realized something uncomfortable: I was unconsciously incompetent. As a native English speaker, I had never interrogated whether the educational abundance my children enjoyed existed for children who spoke other languages. I naively assumed equivalence - that if we had endless options, everyone else did too.
I started digging into this just for fun, out of curiosity. What I found was striking. The contrast between what was available in English versus what existed for minority languages, regional languages, less-resourced languages - the gap was enormous. Families wanted to maintain their cultural and linguistic identity while giving their children modern learning tools, but they were working with a fraction of the resources. Research confirms this isn't just anecdotal - language minority children experience measurable disadvantage in educational contexts, and the resource scarcity compounds that gap.
This felt like an equity problem hiding in plain sight. And it seemed like something that should have been solved already - but clearly wasn't.
The Hypothesis: AI Could Translate at Near-Zero Marginal Cost
In late 2022, ChatGPT was still new. There were no AI agents. No sophisticated automation pipelines. No elegant tools that talked to each other seamlessly. But I saw something in the early LLMs that felt underappreciated: they could translate content not just adequately, but well - with nuance, with tone preservation, at scale, and at near-zero marginal cost per language.

The economic reality mattered. Using ChatGPT dramatically reduced the need for human translators, which would have been prohibitively expensive for an individual creator publishing across 15 languages. The barrier wasn't capital. The barrier was willingness to do the manual work of building something testable.
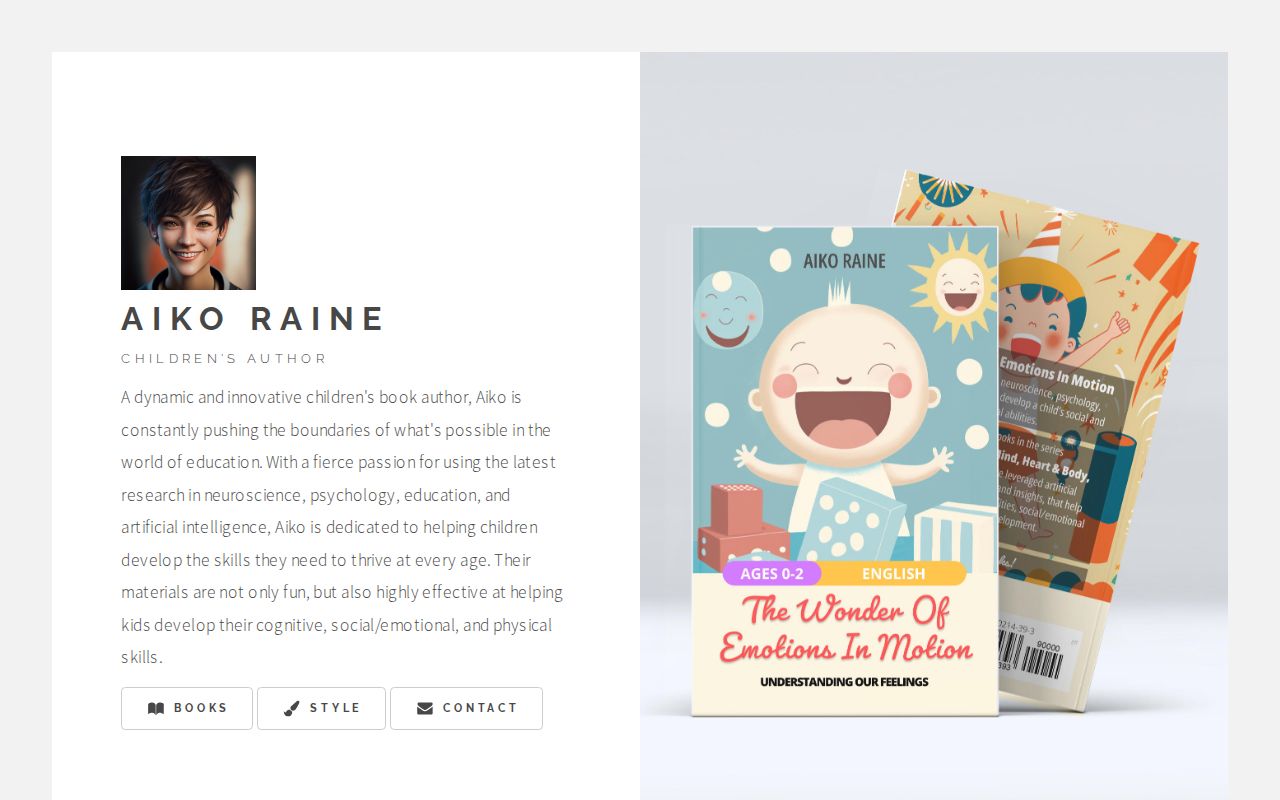
So I decided to test the hypothesis directly. If I could build one good children's book, AI could help me publish it in 15 languages without institutional backing or a translation budget. I would create the "Expanding Abilities: Mind, Heart & Body" series under the pen name Aiko Raine - books designed from the ground up for multilingual publishing, targeting cognitive, social/emotional, and physical development in young children. I already had experience in building and selling products on global Amazon marketplaces and KDP (Kindle Direct Publishing) was a great platform for both print and e-books.


The Build: Tool-Mashing Without Sophistication
The workflow was scrappy, I mean really scrappy. I used ChatGPT for writing and translation. Google Sheets became my content management system, tracking text variations across languages and ensuring consistency and finding deltas from Google Translate. Figma handled layout and typography - and this is where the manual complexity hit hard. Fitting translated text across 15 languages into consistent page designs is genuinely difficult. Some languages are much longer than English. Some are much shorter. Every page required iteration to maintain visual coherence without breaking the design.



Back then Dall-E was state of the art but it was still pretty terrible. So, Photoshop and Illustrator handled the visual asset and illustration augmentation. Nothing talked to anything else automatically. I was duct-taping spreadsheets to design software and hoping the translations held their meaning across cultural contexts.
Then I hit a constraint I hadn't anticipated.
The USPTO Constraint: 20% Modification Required
AI-assisted content raised copyright and authorship issues that I had to account for in the workflow. The key constraint was not a bright-line “20% modification” rule, but the broader requirement that copyright protection only applies to the human-authored elements of a work.
So I built a manual review and revision layer into the process. I read every translation, adjusted phrasing, reworked sentence structure, checked for cultural appropriateness, and verified that the educational purpose remained intact. That added meaningful time and effort, but it clarified something important: even early AI tools could support equity-focused interventions without full automation. The real constraint was not access to advanced infrastructure. It was the willingness to manage human review, iterative editing, and the legal limits around AI-generated material.
The Publication: 15 Languages, Library of Congress, Welsh Included
I published the books in 15 languages - English, Español, Português, Français, Deutsch, Italiano, Polski, Українська, Nederlands, Svenska, עברית, Afrikaans, Norsk, Cymraeg, and Íslenska. For example, Welsh learners consistently report resource scarcity despite government investment in language preservation. The Welsh Government aims for 30% of pupils to be taught in Welsh-medium education by 2031, but families still struggle to find diverse educational materials outside formal school settings.
I registered everything with the Library of Congress. This wasn't a side experiment or a digital curiosity. This was a full publishing operation, built manually, made legitimate through proper registration.
Then I walked away. No updates. No marketing. No iteration. That was 2022.
The Proof: Consistent Purchases Without Marketing
Today, in 2026, I still get purchases across languages from all over the world, Welsh included. I didn't go looking for those readers. They found the books because children who speak those languages, or their parents, don't have a lot of options. The thesis was right. The gap was real. The books filled it.
The sales data validated the hypothesis in ways I hadn't fully anticipated. The majority of my sales are not the English versions. They're being sold in worldwide marketplaces - United States, Canada, Germany, Italy, France, Spain, Japan, etc. The languages aren't limited to their home countries either. In Germany, a lot of Italian books sell. In Italy, Spanish versions move. The demand for low-resource language support is global and persistent.
This pattern mirrors broader trends. By the end of 2025, tools supporting low-resource languages are predicted to increase coverage by 50%, with low-resource language solutions generating $500 million globally. The opportunity is growing, but it remains underexploited because most operators wait for perfect tools rather than building with available apparatus.
The Execution Lesson: Willingness Over Infrastructure
What I learned from this build is that the barrier to solving equity problems with AI in 2023 wasn't access to sophisticated infrastructure. It was willingness to iterate through manual complexity, accommodate legal constraints discovered mid-build, and ship something imperfect that solved a real problem.
The continued downloads prove that the gap persists and that individual execution can address needs that credential-heavy organizations ignore. The Welsh Government invests heavily in language preservation, but institutional efforts focus on formal education pathways. Families need diverse resources outside that structure, and a single person with basic AI tools filled part of that gap.
The Opportunity Others Ignore
This validated approach remains underexploited. The tools available today are exponentially better than what existed in 2022. AI agents exist now. Automation pipelines are more sophisticated. The economic barriers are even lower.
Yet the gap remains. Big tech companies invest in languages that offer strong commercial returns. Minority languages lack financial incentives, so fewer resources get dedicated to their AI development. The opportunity for individual creators to step into this space is even greater now than it was when I started.
The execution lesson isn't about AI capability advancement. It's about the disparity between people who build testable artifacts and people who wait for perfect conditions. While others theorized about what AI could do for underserved communities, I just built the thing with basic tools and manual effort after a friend made a throwaway comment about resource scarcity.
The books are still getting downloaded. The hypothesis was correct. The gap was real.
What problem are you seeing that you're unconsciously incompetent about - and what would it take to just start building a test?